
本文最后更新于1163 天前,其中的信息可能已经过时,如有错误请发送邮件到mapleleaf2333@gmail.com
hadoop架构
在自制的系统中,hadoop的形式如下所示:

一个HDFS集群是有一个Namenode和一定数目的Datanode组成。Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问。Datanode在集群中一般是一个节点一个,负责管理节点上它们附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。Namenode执行文件系统的namespace操作,例如打开、关闭、重命名文件和目录,同时决定block到具体Datanode节点的映射。Datanode在Namenode的指挥下进行block的创建、删除和复制。
个人体会到的HDFS的特性:
- 适合超大文件存储:具有几百MB、几百GB甚至几百TB大小的文件,但不适合小文件存储(占用namenode)
- 要求低时间延迟数据访问的应用,例如几十毫秒范围,不适合在HDFS上运行。HDFS是为高数据吞吐量应用优化的,这可能会以提高时间延迟为代价。
- 容错性较高,数据有多个副本
- 低成本,硬件要求低(4台虚拟机都可以模拟即可看出)
- 在节点间能动态地移动数据,并保证各个节点的动态平衡
启动hadoop后的几个节点:
- NameNode:管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。
- SecondaryNamenode:它不提供NameNode服务,而仅仅是NameNode的一个工具,这个工具帮助NameNode管理元数据信息
- DataNode:是文件系统的工作节点。它们根据需要存储并检索数据块(受客户端或NameNode调度),并且定期向NameNode发送它们所存储的块的列表。
hadoop读数据
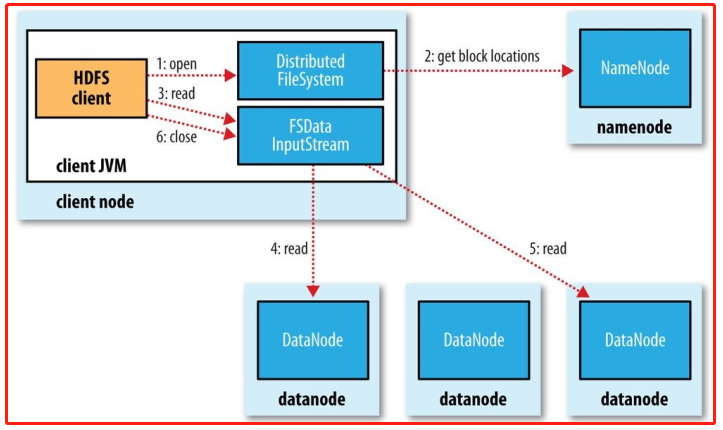
hadoop写数据
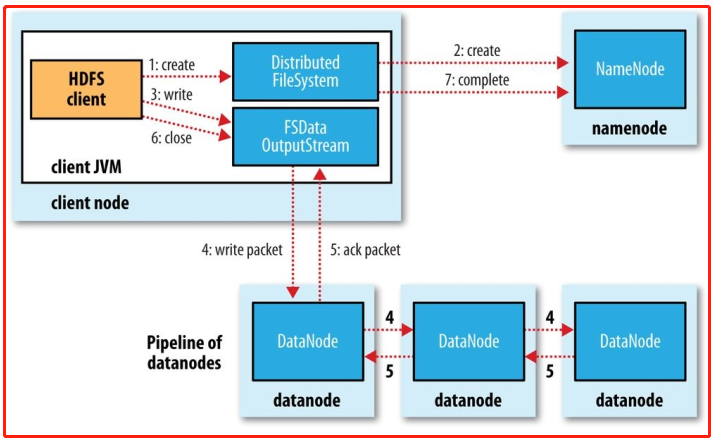
实验流程
启动hadoop,可用的管理页面有:
- hadoop管理页面:http://master:50070/
- hadoop状态页面:http://master:8088/
1.检验文件上传下载
//在Master进行
//先进行文件的创建
echo test > test.txt
//创建文件夹
hadoop fs -mkdir /itcast
//文件上传
hadoop fs -put test.txt /itcast
//在Slave1进行
//下载文件
hadoop fs -get /itcast/test.txt 2.检验文件一致性特性
//在Master上进行
//创建文件
echo 1111 > new_1.txt
echo 22222yeah > new_2.txt
echo 3333haha > new_3.txt
hadoop fs -put new_1.txt /
//在其他节点查看
hadoop fs -cat /new_1.txt
//在Master上进行文件数据追加
hadoop fs -appendToFile new_2.txt new_3.txt /new_1.txt
//在各个节点查看
hadoop fs -cat /new_1.txt3.文件分块与备份
可以通过直接查看管理页面了解。
hadoop备份的是数据块(就是将每个文件分割为128M大小的数据块,不够的按128M进行存储),对每个数据块进行备份,然后存放到子节点上(并且每个子节点上存放的不会是同一个数据块)。
假如备份数为3份,就会把文件分割后的每个数据块进行备份,存放到不同的子节点上,当一个子节点出现异常,就会通过反馈机制将信息反馈给主节点,主节点就会将该节点上的数据块进行重新备份存放到其他子节点上,使得数据块的备份数保持在自定义数。这样就可以保证数据不会丢失,体现了hadoop的容错性。
常用命令总结
//打印文件系统所有文件
hadoop fs -ls /
//创建文件
hadoop fs -touch /file.txt
//创建文件夹
hadoop fs -mkdir /itcast
//从节点上传文件到系统
hadoop fs -put test.txt /itcast
//从节点下载文件
hadoop fs -get /README.txt ./
//数据移动
hadoop fs -mv <src> ... <dst>
//追加数据
hadoop fs -appendToFile 2.txt 3.txt /1.txt
//读取文件
hadoop fs -cat /itcast/test
//删除文件
hadoop fs -rm -r /file.txt









