本文最后更新于916 天前,其中的信息可能已经过时,如有错误请发送邮件到mapleleaf2333@gmail.com
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
hive架构
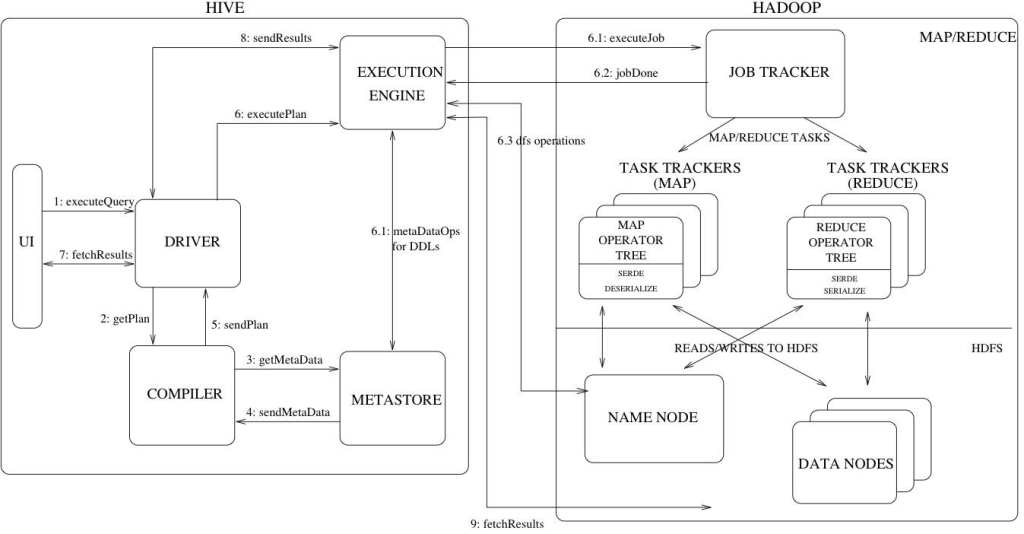
服务组件:
- Driver组件:该组件包括:Compiler、Optimizer、Executor,它可以将Hive的编译、解析、优化转化为MapReduce任务提交给Hadoop1中的JobTracker或者是Hadoop2中的SourceManager来进行实际的执行相应的任务。
- MetaStore组件:存储着hive的元数据信息,将自己的元数据存储到了关系型数据库当中,支持的数据库主要有:Mysql、Derby、支持把metastore独立出来放在远程的集群上面,使得hive更加健壮。元数据主要包括了表的名称、表的列、分区和属性、表的属性(是不是外部表等等)、表的数据所在的目录。
- 用户接口:CLI(Command Line Interface)(常用的接口:命令行模式)、Client:Hive的客户端用户连接至Hive Server ,在启动Client的时候,需要制定Hive Server所在的节点,并且在该节点上启动Hive Server、WUI:通过浏览器的方式访问Hive。
运作流程:
- 用户提交查询等任务给Driver。
- 编译器获得该用户的任务Plan。
- 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
- 将最终的计划提交给Driver。
- Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
- 获取执行的结果。
- 取得并返回执行结果。
个人体会到的特性:
- hive的优势在于将SQL转化为Mapreduce作业,在简化mapreduce的同时,优化其操作
- hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;hive的表本质就是Hadoop的目录/文件
- 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差
hive常用命令
//查看表(选定数据库后)
show tables;
//查看表的格式
desc product;
//直接插入数据
insert into customer (id,name,phone) values(1,'Tom','66308200');
//将本地数据插入到表中
load data local inpath '/usr/hadoop/customer.txt' into table customer;
//将本地数据覆盖到表中
load data local inpath '/usr/hadoop/customer.txt' OVERWRITE INTO TABLE customer;
//创建表
//表内数据用'\t'分割(即“Tab按键”)
CREATE TABLE orderTable(id int,customer_id int,order_date date,offer_date date)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
create table if not exists movie(
movie_id string,
movie_name string,
directors array<string>,
actors array<string>)
row format delimited
fields terminated by '|'
collection items terminated by '%';
create table if not exists movie_other(
movie_id string,
movie_name string,
other_id string)
row format delimited
fields terminated by '|'
collection items terminated by '%';
//装数据
load data local inpath '/home/hadoop/hive_movie_director_actor.txt' OVERWRITE INTO TABLE movie;
load data local inpath '/home/hadoop/hive_movie_other.txt' OVERWRITE INTO TABLE movie_other;
//修改表名
alter table movie_director_actor rename to movie;
使用HIve进行数据分析
数据分析功能示例
还有很多强大的数据分析功能、ETL功能
//选择前十条数据
select * from movie limit 5;//查看前10位用户对商品的行为
//计算表内条数
select count(*) from product;//用聚合函数count()计算出表内有多少条行数据
//在函数内部加上distinct,查出uid不重复的数据有多少条
select count(distinct id) from customer;*//在函数内部加上distinct,查出uid不重复*案例:查询不重复的数据有多少条(为了排除客户刷单情况)
hive>select count(*) from (select uid,item_id,behavior_type,item_category,visit_date,province from bigdata_user group by uid,item_id,behavior_type,item_category,visit_date,province having count(*)=1)a;
//查找包含特定人物的电影
select movie_name from movie where array_contains(actors, 'RobertDowneyJr.')=true;
//查找包含特定导演的电影
select movie_name from movie where array_contains(directors, 'FrancisFordCoppola')=true;