HBase配置
通过查阅相关资料,基于已建立的hadoop集群,完成个人服务器的hbase搭建,具体配置如下: <property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave1:2181</value>
</property>Regionserver只设置本机,通过start-hbase.sh启动后,jps查看结果如下:
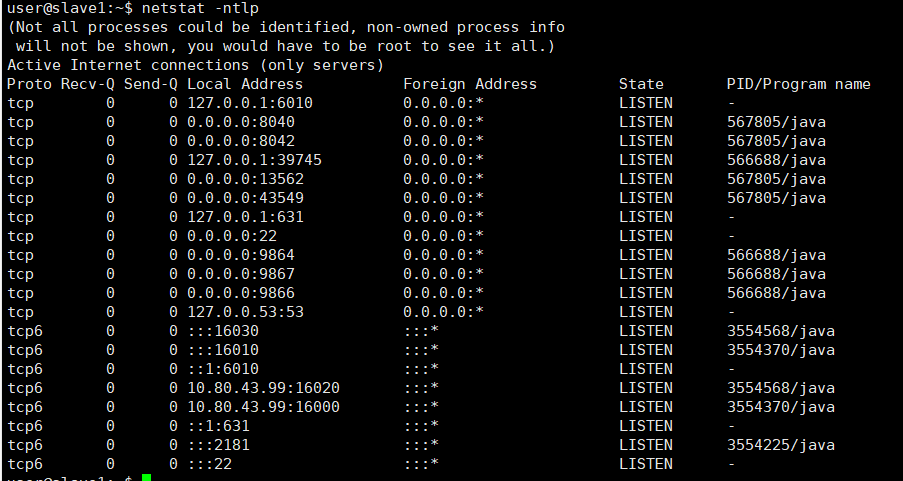
通过命令netstat -ntlp查看网络情况,相关端口都是可访问的,相关进程已启动:
模拟实践
基于微博谣言话题中部分意见领袖结节关系图谱,利用Hbase进行简单的数据存储。
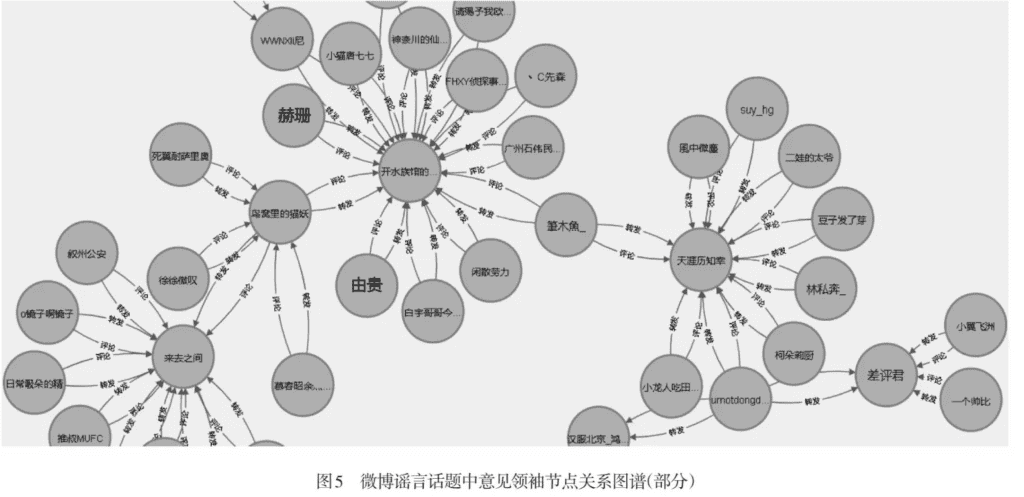
表设计
为了较好地描述微博谣言话题中,不同用户之间发生评论、转发等关系的结节关系图谱,采用如下设计:
- 表名:weibo_relations
- Row Key: 采用自定义的唯一标识符字符串来表示
- 列族:relations
- 列族中的列限定符:
- source_user:表示源用户的用户名
- target_user:表示目标用户的用户名
- action_type:表示用户之间的交互类型(例如评论、转发等)
- timestamp:表示交互发生的时间戳
这个设计中将每个用户之间的交互关系表示为一条数据,并赋予一个唯一的标识符Row Key,在列族中使用四个限定符描述一个完整的交互关系。
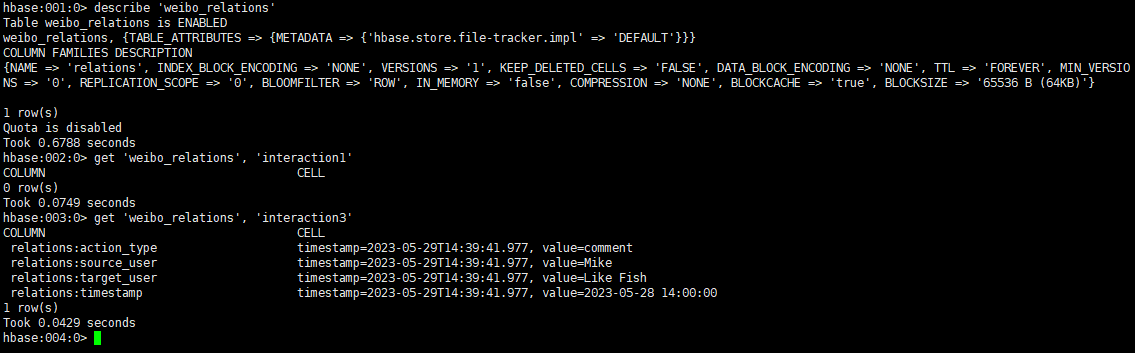
我们首先通过hbase shell进行一些基本的操作:
- 使用命令
create 'weibo_relations', 'relations'完成表的创建(实际上这一步也可以通过java完成),并根据上面的设计插入一部分测试数据 - 确认表的结构,命令:
describe 'weibo_relations',通过get 'weibo_relations', 'interaction3'查看测试数据,结果如下:
Java连接程序的实现
hbase shell在使用上会有一些麻烦,在java中,基于需求,使用hbase提供的API实现了更多的功能,功能如下:
- 创建一张表
- 插入一条关系
- 删除一条关系
- 基于Row key查询数据
- 删除一条关系
- 删除表
- 删除一个用户的所有关系
在代码中,通过如下内容完成了hbase连接的配置:
private static final String HBASE_ZOOKEEPER_QUORUM = "10.80.43.99";
private static final String HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT = "2181";
private static final String TABLE_NAME = "weibo_relations";
private static final String CF_RELATIONS = "relations";
Configuration config = HBaseConfiguration.create();
config.set(HConstants.ZOOKEEPER_QUORUM, HBASE_ZOOKEEPER_QUORUM);
config.set(HConstants.ZOOKEEPER_CLIENT_PORT, HBASE_ZOOKEEPER_PROPERTY_CLIENT_PORT);下面介绍一下几个比较重要的功能的实现:
添加一条关系
private static void addRelation(Connection connection, TableName tableName, String interactionId, String sourceUser, String targetUser, String actionType, String timestamp) throws IOException {
try (Table table = connection.getTable(tableName)) {
Put put = new Put(Bytes.toBytes(interactionId));
put.addColumn(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("source_user"), Bytes.toBytes(sourceUser));
put.addColumn(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("target_user"), Bytes.toBytes(targetUser));
put.addColumn(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("action_type"), Bytes.toBytes(actionType));
put.addColumn(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("timestamp"), Bytes.toBytes(timestamp));
table.put(put);
System.out.println("关系添加成功");
}
}在本函数中,主要是先通过Table获得hbase中需要进行操作的表,通过HBase的API提供的Put对象,传入交互ID作为行键,然后对列族的每个列限定符值通过Byte传值完成数据的插入。
删除一条关系
//删除关系
private static void deleteRelation(Connection connection, TableName tableName, String interactionId) throws IOException {
try (Table table = connection.getTable(tableName)) {
Delete delete = new Delete(Bytes.toBytes(interactionId));
table.delete(delete);
System.out.println("关系删除成功");
}
}删除某一行的关系其实比较简单,只需获取表后,传入行的RowKey,即可完成删除。
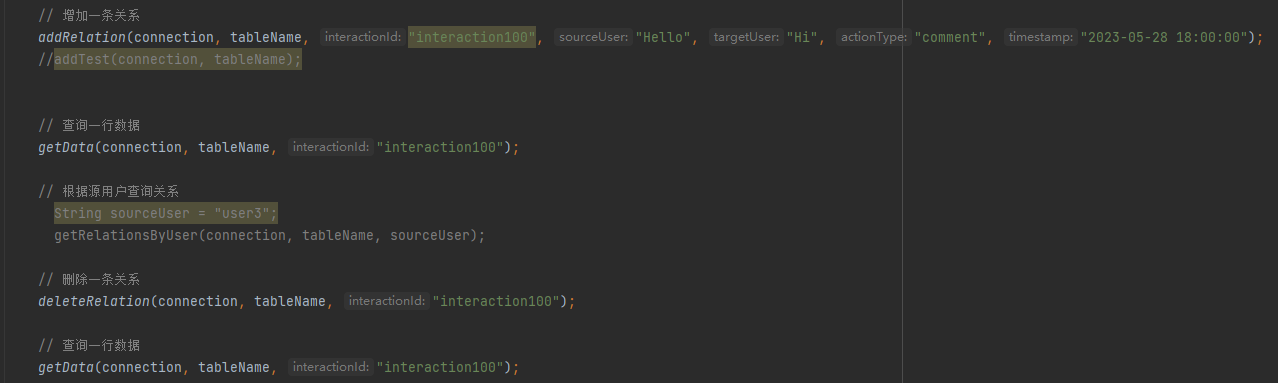
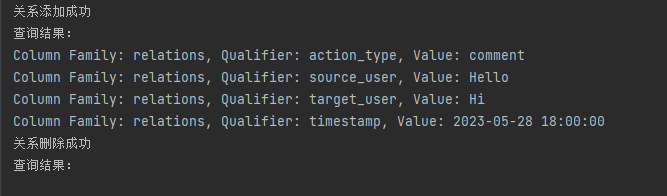
演示1
对于上面的部分功能实现,现在设计一个场景,先插入一条关系,然后查询该关系,再将该关系删除,再次查询,以下是演示结果:
查询一个源用户的所有关系
private static void getRelationsByUser(Connection connection, TableName tableName, String sourceUser) throws IOException {
System.out.println("\n查询指定源用户'"+sourceUser+"'的结果如下:");
try (Table table = connection.getTable(tableName)) {
Scan scan = new Scan();
scan.setFilter(new SingleColumnValueFilter(Bytes.toBytes(CF_RELATIONS),
Bytes.toBytes("source_user"), CompareOperator.EQUAL, Bytes.toBytes(sourceUser)));
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
byte[] rowKey = result.getRow();
byte[] targetUserBytes = result.getValue(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("target_user"));
byte[] actionTypeBytes = result.getValue(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("action_type"));
byte[] timestampBytes = result.getValue(Bytes.toBytes(CF_RELATIONS), Bytes.toBytes("timestamp"));
String targetUser = Bytes.toString(targetUserBytes);
String actionType = Bytes.toString(actionTypeBytes);
String timestamp = Bytes.toString(timestampBytes);
System.out.println("Source User: " + sourceUser);
System.out.println("Target User: " + targetUser);
System.out.println("ActionType: " + actionType);
System.out.println("Timestamp: " + timestamp);
System.out.println("-------------------");
}
scanner.close();
}
}在实际查询中,相比于通过行键进行查询,更常见的查询是查某一个用户的关系,我设计了一个查询源用户(操作用户)执行的所有关系的函数,如上所示。这里主要用到的有两个,一个是Scan对象,用于扫描表中的数据;另一个是SingleColumnValueFilter对象;两者配合能够筛选特定的参数。然后通过table自带的getScanner获取结果扫描器,用于迭代匹配的行。
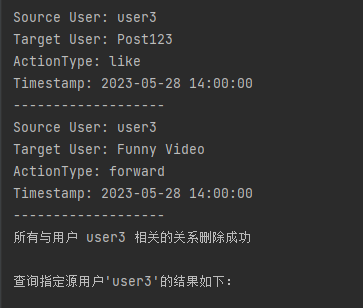
我们以查询’user3’的关系为例,结果如下:
删除指定用户的所有关系(删除一批关系)
//删除指定用户的所有关系
private static void deleteRelationsByUser(Connection connection, TableName tableName, String user) throws IOException {
try (Table table = connection.getTable(tableName)) {
Scan scan = new Scan();
scan.setFilter(new SingleColumnValueFilter(Bytes.toBytes(CF_RELATIONS),
Bytes.toBytes("source_user"), CompareOperator.EQUAL, Bytes.toBytes(user)));
ResultScanner scanner = table.getScanner(scan);
List<Delete> deleteList = new ArrayList<>();
for (Result result : scanner) {
byte[] rowKey = result.getRow();
Delete delete = new Delete(rowKey);
deleteList.add(delete);
}
scanner.close();
if (!deleteList.isEmpty()) {
table.delete(deleteList);
System.out.println("所有与用户 " + user + " 相关的关系删除成功");
} else {
System.out.println("未找到与用户 " + user + " 相关的关系");
}
}
}同样的,在删除一批关系的时候,我们更多的操作是删除一个用户的所有关系,整体的方式与查询指定用户相似,都是通过scan对象和SingleColumnValueFilter对象进行过滤,然后删除的逻辑则跟前面的删除一条关系类似,以’user3’为例,结果如下: