

1.基本介绍
REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库。它是一个开源的,使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,它提供了多种语言的 API。Redis提供了一个快速、可靠和灵活的解决方案,常常被用于高性能的键值存储和数据缓存。
Redis 还通常被称为数据结构服务器,因为值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等类型。
2. 特点
2.1 技术特点
- 数据结构多样性:Redis支持多种数据结构,包括字符串、哈希、列表、集合、有序集合等。这使得Redis能够灵活地存储和处理各种类型的数据,并提供适合不同场景的数据模型。
- 丰富的操作命令:Redis提供了丰富的操作命令,使开发人员能够方便地对数据进行增删改查和其他操作。无论是对单个键值对进行操作,还是对数据结构进行复杂的操作,Redis都提供了相应的命令和API。
- 发布/订阅模式:Redis支持发布/订阅模式,使得多个客户端能够实现消息传递和事件通知机制。这种模式下,发布者可以将消息发布到指定的频道,而订阅者可以订阅感兴趣的频道并接收到相应的消息。
- 事务支持:Redis支持事务操作,开发人员可以将一组操作打包成一个原子性操作,要么全部执行成功,要么全部不执行。这保证了在多个操作之间的数据一致性,并且可以提高操作的执行效率。
- 分布式支持:Redis具备一些分布式特性,如主从复制和分片。主从复制可以实现数据的热备份和故障恢复,提高系统的可靠性和可用性。而分片则可以将数据分散存储在多个节点上,实现水平扩展和负载均衡。
2.2 性能特点
- 高速读写能力:由于数据存储在内存中,Redis能够实现非常快速的读写操作。这使得它成为处理大量并发请求和高速读取的理想选择。
- 响应时间低延迟:Redis的内存存储和优化的数据结构使得它能够在极短的时间内响应客户端请求,实现低延迟的数据访问和操作。
- 高并发支持:Redis通过使用事件驱动、异步IO和多路复用等技术,能够同时处理成千上万个并发连接,保持高吞吐量和良好的性能表现。
- 持久化支持:Redis提供持久化功能,可以将数据定期保存到磁盘上,以防止系统故障或重启导致数据丢失。这确保了数据的持久性和可靠性。
- 扩展性和负载均衡:Redis具备良好的可扩展性,可以通过添加更多的节点和使用分片等技术来扩展存储容量和处理能力,从而实现负载均衡和水平扩展。
3. 应用场景
Redis在许多不同的应用场景中被广泛使用,我简单列举一下一些常见的应用场景:
- 缓存:Redis最常见的用途之一是作为缓存层。由于Redis基于内存存储,读写速度非常快,适用于高频读取的场景。将热门数据存储在Redis中可以提高系统的响应速度,并减轻后端数据库的负载。
- 会话存储:Redis可以用作会话存储,将用户会话数据存储在内存中,以提供快速的用户认证和状态管理。它可以用于构建高性能的用户登录系统、购物车功能、用户偏好设置等。
- 实时消息传递:Redis提供了发布-订阅(Pub/Sub)功能,可以用于实时消息传递和事件通知。它可以用于构建聊天应用、实时数据更新通知、实时推送等场景。
- 具有地理空间信息的应用:Redis支持地理位置索引和半径查询,因此适用于构建基于地理位置的应用,如位置服务、附近的人功能、地理围栏等。
- 计数器和排行榜:Redis的原子操作和快速写入能力使其非常适合实现计数器和排行榜功能。可以使用Redis来实时计算和更新用户的点赞数、浏览次数、排名等。
- 分布式锁:Redis提供了分布式锁的支持,可以用于多个应用实例之间的协调和互斥访问。分布式锁可用于避免并发冲突、控制资源访问和实现分布式任务调度等。
- 数据缓存和预取:Redis可以用作持久化缓存,将频繁访问的数据存储在内存中,以提高读取速度。同时,它还支持数据预取功能,可以在系统空闲时预取一些数据,以提前加载到内存中,提高数据的访问效率。
综上所述,Redis的通常作用便是减轻数据库压力,提供更高的查询效率,常常用在token生成、session共享、分布式锁、自增id、验证码等业务场景中。
4. 工作原理
Redis之所以响应快,且平时常说的Redis是单线程的,是因为:Redis采用多路复用epoll+自己实现的事件框架,由内核监视套接字描述符,IO多路复用器将请求放入队列中,然后由事件分派器将队列中的不同请求事件分发到不同的事件处理器(这一步是多线程工作的),再有服务器处理具体的请求(这一步是单线程的,但是由于Redis是基于内存的,所以单线程避免了多线程带来的上下文切换以及处理并发的开销,单线程反而更有优势),最后将数据返回给事件处理器并返回给客户端。
下面将分别讲解其底层的原理:
4.1 I/O复用模型和Reactor 设计模式
4.1.1 I/O 多路复用介绍
I/O指的是网络I/O。多路指的是多个TCP连接(Socket或Channel)。复用指的是复用一个或多个线程。它的基本原理就是不再由应用程序自己监视连接,而是由内核替应用程序监视文件描述符。
客户端在操作的时候,会产生具有不同事件类型的socket。在服务端,I/O 多路复用程序(I/OMultiplexingModule)会把消息放入队列中,然后通过文件事件分派器(File event Dispatcher),转发到不同的事件处理器中。
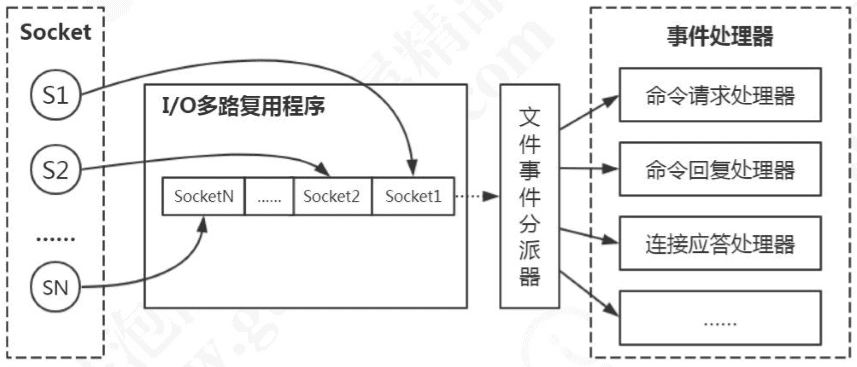
多路复用有很多的实现,以select为例,当用户进程调用了多路复用器,进程会被阻塞。内核会监视多路复用器负责的所有socket,当任何一个socket的数据准备好了,多路复用器就会返回。这时候用户进程再调用read操作,把数据从内核缓冲区拷贝到用户空间。
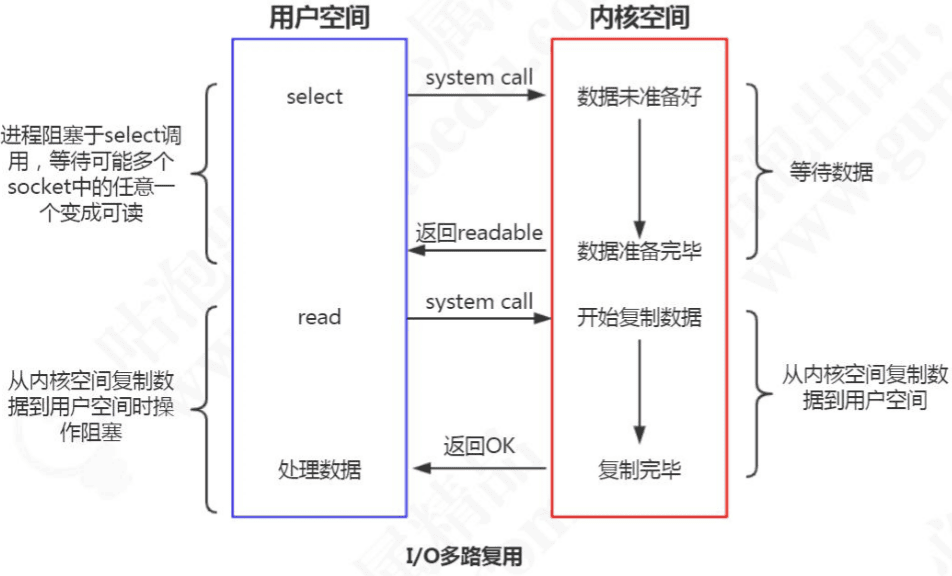
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪(readable)状态, select()函数就可以返回。简而言之,I/O 多路复用其实是在单个线程中通过记录跟踪每一个sock(I/O流) 的状态来管理多个I/O流。
4.1.2 Redis中的I/O多路复用封装
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口。
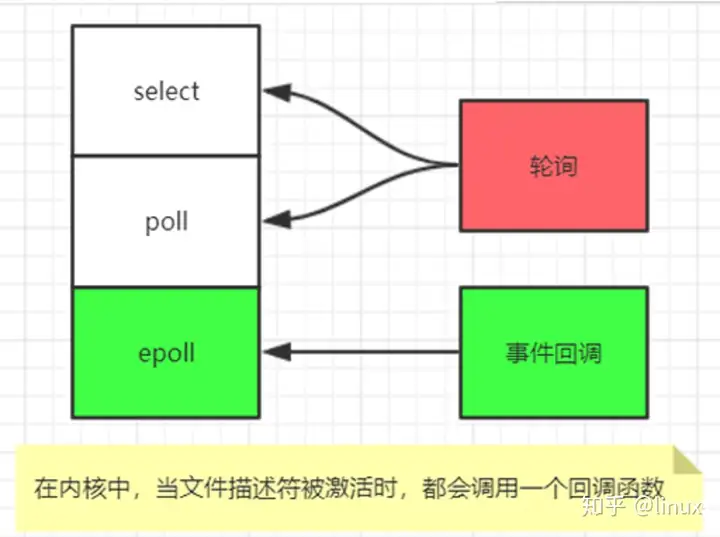
redis的多路复用, 提供了select, epoll, evport, kqueue几种选择,在编译的时候来选择一种:
- select是POSIX提供的, 一般的操作系统都有支撑;
- epoll 是LINUX系统内核提供支持的;
- evport是Solaris系统内核提供支持的;
- kqueue是Mac 系统提供支持的;
为了将所有 IO 复用统一,Redis 为所有 IO 复用统一了类型名 aeApiState,对于 epoll 而言,类型成员就是调用 epoll_wait所需要的参数。接下来就是一些对epoll接口的封装了:包括创建 epoll(epoll_create),注册事件(epoll_ctl),删除事件(epoll_ctl),阻塞监听(epoll_wait)等。
- 创建 epoll 就是简单的为 aeApiState 申请内存空间,然后将返回的指针保存在事件驱动循环中
- 注册事件和删除事件就是对 epoll_ctl 的封装,根据操作不同选择不同的参数
- 阻塞监听是对 epoll_wait 的封装,在返回后将激活的事件保存在事件驱动中
4.1.3 Reactor 设计模式:事件驱动循环流程
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
当 main 函数初始化工作完成后,就需要进行事件驱动循环,而在循环中,会调用 IO 复用函数进行监听。在初始化完成后,main 函数调用了 aeMain 函数,传入的参数就是服务器的事件驱动。
Redis 对于时间事件是采用链表的形式记录的,这导致每次寻找最早超时的那个事件都需要遍历整个链表,容易造成性能瓶颈。而 libevent 是采用最小堆记录时间事件,寻找最早超时事件只需要 O(1) 的复杂度。
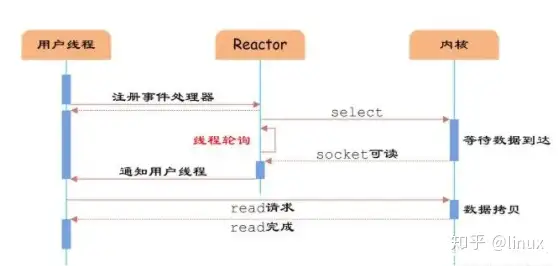
如上图,IO多路复用模型使用了Reactor设计模式实现了这一机制。通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。
用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select/epoll函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select/epoll函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
4.1.4 Redis线程模型
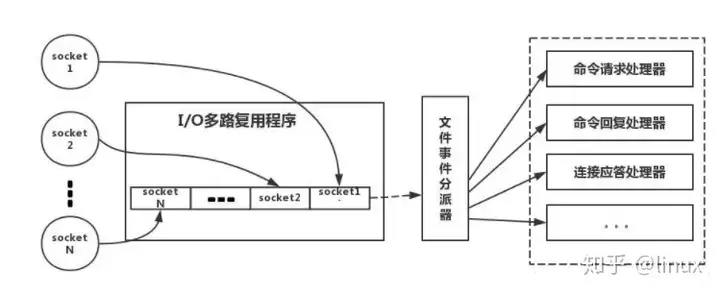
简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,IO事件分派器,依次去队列中取,转发到不同的事件处理器中。
4.2 Redis的内存回收
内存回收主要分为两类,一类是key过期,一类是内存使用达到上限(max_memory)触发内存淘汰。可以通过expire、pexpire、expireAt、pexpireAt设置键的过期时间,实际前三个命令也是转化成pexpireAt去执行。
Redis使用expires 字典保存了所有键的过期时间,称为过期字典。
- 过期字典的键是一个指针,指向键空间中的键对象(所以不会出现任何重复对象,也不会浪费任何内存)
- 过期字典的值是一个long long 类型的整数,保存了过期时间(一个毫秒级的UNIX时间戳)
如下是其源码:
typedef struct redisDb{
dict *dict; /* 所有的键值对 */
dict *expires; /* 设置了过期时间的键值对 */
dict *blocking_keys; /*Keys withclientswaitingfordata(BLPOP)*/
dict *ready_keys; /*BlockedkeysthatreceivedaPUSH*/
dict *watched_keys; /*WATCHEDkeysforMULTI/EXECCAS*/
int id; /*DatabaseID*/
long long avg_ttl; /*Average TTL,justforstats*/
list *defrag_later; /*Listofkeynamestoattempttodefragonebyone,gradually.*/
}redisDb;4.2.1 过期策略
Redis中主要同时使用惰性删除和定期删除策略:
- 惰性删除:只有访问一个key的时候才会判断该key是否过期,过期则清除,不过期则返回。虽然对CPU友好,但是如果大量过期键不再被访问,会导致大量内存被占用。
- 定期删除:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。定期删除函数activeExpireCycle工作模式如下:
- 在规定时间内,分多次遍历服务器中各个数据库,每次从数据库的过期expires 字典中随机取出一部分键进行检查,过期则删除。
- 由全局变量current_db 记录函数的执行进度(记录是几号数据库),下次再执行时从当前位置开始。当把所有数据库都遍历完成,current_db 重置为0。
4.2.2 不同持久化模式对过期键的处理
- RDB模式:当执行SAVE或BGSAVE命令创建一个新的RDB文件时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的RDB文件中。在启动Redis服务器载入RDB文件时,如果服务器为master节点,则过期键会被忽略,不会载入到数据库中;如果服务器为slave节点,则不论键是否过期,都会被载入到数据库中。
- AOF模式:当服务器以AOF模式运行时,AOF文件不会因过期键而产生任何影响,而是当过期键被删除后,程序会向AOF文件追加一条DEL命令,来显示记录该键已被删除。但是AOF重写过程中,处理过期键类似RDB文件,过期键不会被保存到重写后的AOF文件中。
- 复制模式:当服务器以复制模式运行时,slave节点过期键的删除由master节点控制,即使从服务器执行客户端的读请求遇到过期键,也像处理未过期键一样,所以在该模式下,对主从节点上的过期键访问时可能会得到不一样的结果。
4.2.3 淘汰策略
redis的内存淘汰策略,是指当内存使用达到最大极限时,使用淘汰算法来决定清理部分数据,以保证新数据的存储。这里的最大内存是可以通过修改redis.conf参数配置:maxmemory <bytes>来改变的。常用的淘汰策略如图所示:
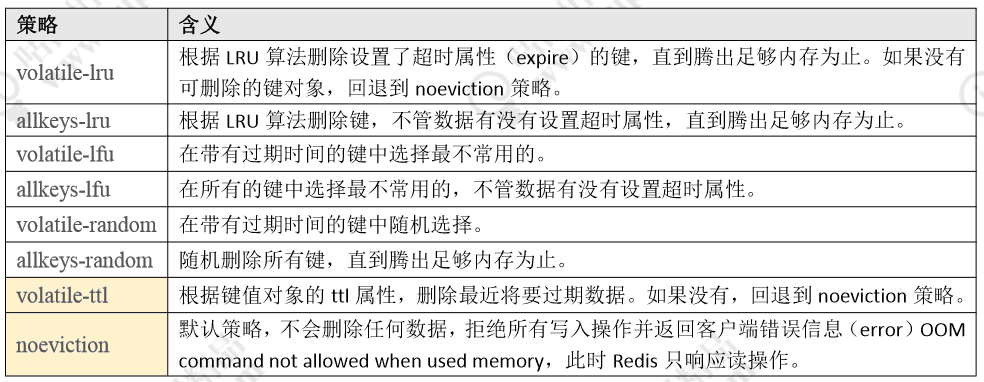
常见的淘汰算法有:
- LRU,Least Recently Used:最近最少使用。判断最近被使用的时间,距离当前时间最远的数据优先被淘汰。Redis LRU和传统的LRU有所不同。传统LRU需要额外的数据结构存储,消耗内存。Redis LRU通过随机采样来调整算法的精度。根据配置的采样值maxmemory_samples(默认是5个)随机从数据库中选择m个key,淘汰其中热度最低的key。所以采样参数m配置的数值越大,就能越精确的查找到待淘汰的数据,但是 也消耗更多的CPU计算,执行效率降低。
- LFU,Least Frequently Used:基于访问频率的淘汰机制。
4.3 持久化机制
4.3.1 RDB
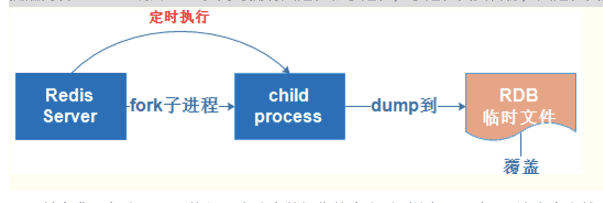
RDB是redis默认的持久化方案。当满足一定条件时,会把当前内存中的数据写入磁盘,生成一个快照文件dump.rdb。实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。redis重启会通过加载dump.rdb文件恢复数据。
4.3.2 AOF
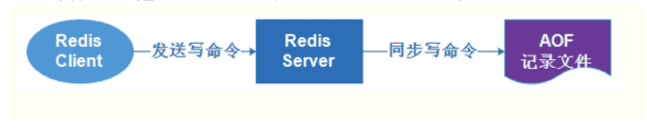
Redis 默认不开启AOF。AOF采用日志的形式来记录每个写操作,并追加到文件中。开启后,执行更改Redis数据的命令时,就会把命令写入到AOF文件中。Redis 重启时会根据日志文件的内容把写指令从前到后执行一次以完成数据的恢复工作。
4.3.3 两种方案的比较
如果可以忍受一小段时间内数据的丢失,毫无疑问使用 RDB 是最好的,定时生成RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快。
否则就使用 AOF 重写。但是一般情况下建议不要单独使用某一种持久化机制,而是应该两种一起用,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
由于RDB持久化会造成数据丢失,而AOF恢复数据的时间较慢,未解决这个问题,Redis4.0开始支持混合持久化模式(4.0默认关闭,5.0默认开启),混合持久化由AOF的bgrewriteaof(重写)触发,先将重写命令执行钱的内存进行RDB快照,将RDB快照内容写入到新的AOF文件,然后将增量的AOF写操作命令也写入新的AOF文件,最后用新的AOF文件替换旧的AOF文件。混合模式下的AOF文件,前面是AOF格式,后面是RDB格式。
5. 部署使用方法
5.1 部署
在部署方面,可以考虑采用docker的方式进行部署,以下将我在自己服务器上部署的具体步骤记录下来:
5.1.1 部署准备
首先通过docker pull redis将Redis的镜像安装到服务器上,(服务器之前就试过安装redis)具体如截图:

然后准备Redis的配置文件,这里我们去redis的官方去下载一个redis使用里面的配置文件,redis中文官方网站。将其下载后解压,得到redis.conf文件。我们修改redis.conf配置文件,主要配置如下:
bind 127.0.0.1 #注释掉这部分,使redis可以外部访问
daemonize no#用守护线程的方式启动
requirepass 密码#给redis设置密码
appendonly yes#redis持久化 默认是no
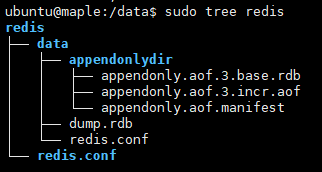
tcp-keepalive 300 #防止出现远程主机强迫关闭了一个现有的连接的错误 默认是300在本地创建与docker映射的目录,因为我的docker的一些配置文件都是存放在”/data”目录下面的,所以我依然在”/data”目录下创建一个”redis”目录,这样是为了方便后期管理,把刚刚创建好的文件拷贝过去,具体截图如下所示:
5.1.2 启动docker
使用如下命令启动Redis
sudo docker run -p 6379:6379 --name redis_new -v /data/redis/redis.conf:/etc/redis/redis.conf -v /data/redis/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes参数解释:
-p 6379:6379:把容器内的6379端口映射到宿主机6379端口 -v /data/redis/redis.conf:/etc/redis/redis.conf:把宿主机配置好的redis.conf放到容器内的这个位置中 -v /data/redis/data:/data:把redis持久化的数据在宿主机内显示,做数据备份 redis-server /etc/redis/redis.conf:这个是关键配置,让redis不是无配置启动,而是按照这个redis.conf的配置启动 –appendonly yes:redis启动后数据持久化
通过命令 sudo docker ps 查看redis是否正常启动:

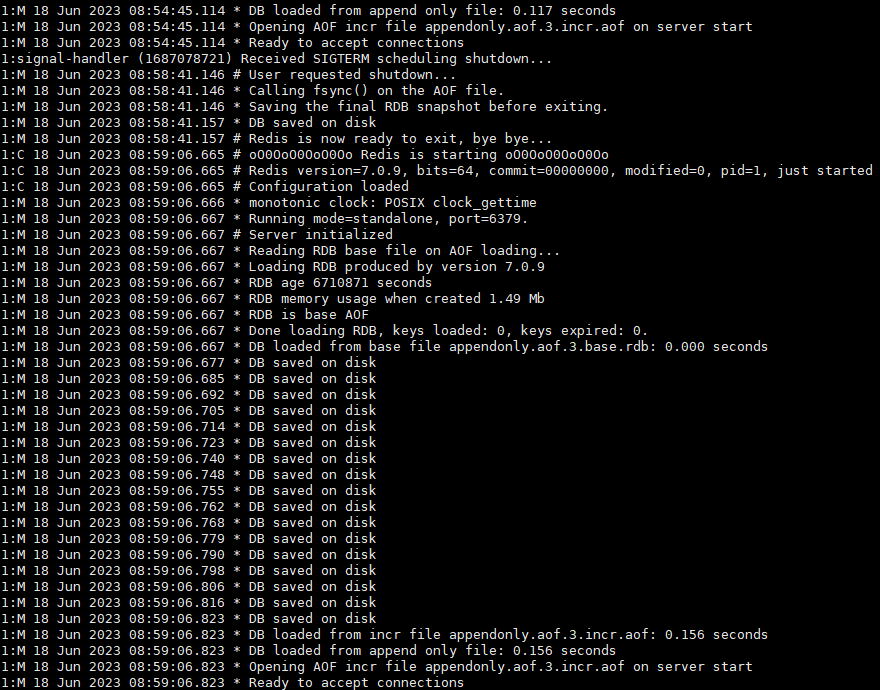
也可以查看redis日志:sudo docker logs redis_new
注意要将防火墙的该端口关闭以开放端口,通过“netstat -ntlp”查看网络状态,看到6379端口已被占用,可知服务已启动:


至此Redis部署完毕。
5.2 Redis的简单使用
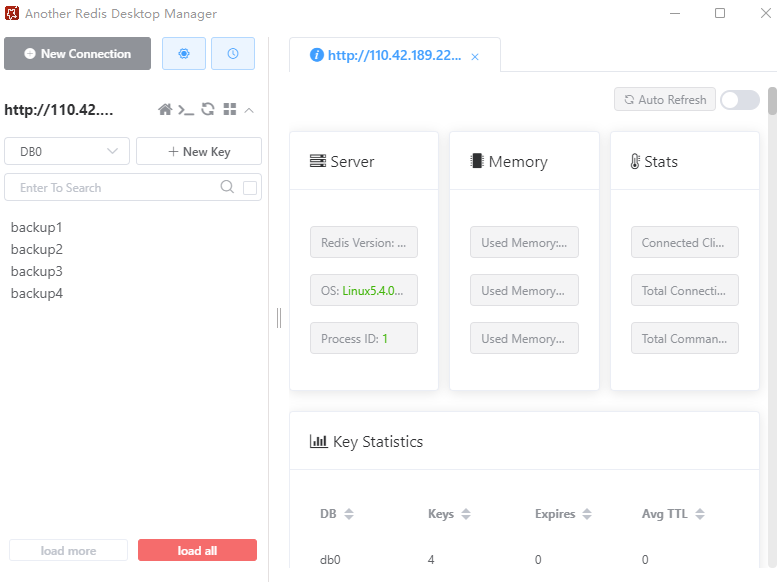
在Redis的使用方面,我通过一个开源的可视化工具“Another Redis Desktop Manager”工具来完成对Redis的监测:
5.2.1 连接服务
我们新建一个java的maven项目,引入依赖:
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.0.0-alpha2</version>
</dependency>
</dependencies>通过以下代码尝试连接Redis服务:
import redis.clients.jedis.Jedis;
public class RedisJava {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("http://mapleleaf666.vip:6379");
System.out.println("连接成功");
//查看服务是否运行
System.out.println("服务正在运行: "+jedis.ping());
}
}运行结果如下,说明服务连接成功:

5.2.2 命令行使用
通过sudo docker exec -it redis_new redis-cli可以进入Redis的命令行界面。
常用命令如下:
# 启动服务
> redis-server [--port 6379]
# 如果命令参数过多,建议通过配置文件来启动Redis。
> redis-server [xx/xx/redis.conf]
# 连接Redis
> ./redis-cli [-h 127.0.0.1 -p 6379]
# 停止Redis(两条命令效果一样)
> redis-cli shutdown
> kill redis-pid
# 测试连通性
127.0.0.1:6379> ping
PONG
# 获取所有键
127.0.0.1:6379> keys *
# 获取键总数
127.0.0.1:6379> dbsize
# 查询键是否存在
127.0.0.1:6379> exists javastack java
# 删除键
127.0.0.1:6379> del java javastack
# 查询键类型
127.0.0.1:6379> type javastack
# 移动键:如把javastack移到2号数据库。
127.0.0.1:6379> move javastack 2
127.0.0.1:6379> select 2
127.0.0.1:6379[2]> keys *
# 更改键名称
127.0.0.1:6379[2]> rename javastack javastack123
# 查询key的生命周期(秒)
127.0.0.1:6379[2]> ttl javastack
# 设置过期时间
127.0.0.1:6379[2]> expire javastack 60
# 设置永不过期
127.0.0.1:6379[2]> persist javastack以上仅为极少的一部分操作命令,具体命令可以去看官方文档,下面做一些简单的演示:
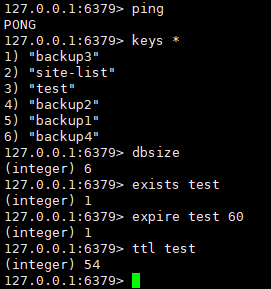
5.2.3 Java简单使用
设计一个简单的函数进行字符串的操作:
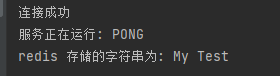
public static void setKey(Jedis jedis){
//设置 redis 字符串数据
jedis.set("test", "My Test");
// 获取存储的数据并输出
System.out.println("redis 存储的字符串为: "+ jedis.get("test"));
}在main调用该函数,运行结果与可视化界面的结果如下所示:
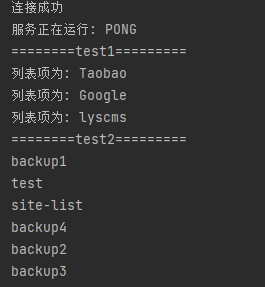
我们设计了如下一个测试函数,主要包含两个测试,测试1是先将创建一个列表存放键,然后将该列表打印出来;测试2是获取所有的key并将key打印出来。
public static void smallTest(Jedis jedis){
System.out.println("========test1=========");
//存储数据到列表中
jedis.lpush("site-list", "lyscms");
jedis.lpush("site-list", "Google");
jedis.lpush("site-list", "Taobao");
// 获取存储的数据并输出
List<String> list = jedis.lrange("site-list", 0 ,2);
for(int i=0; i<list.size(); i++) {
System.out.println("列表项为: "+list.get(i));
}
System.out.println("========test2=========");
// 获取数据并输出
Set<String> keys = jedis.keys("*");
Iterator<String> it=keys.iterator() ;
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}
}具体结果如下所示:
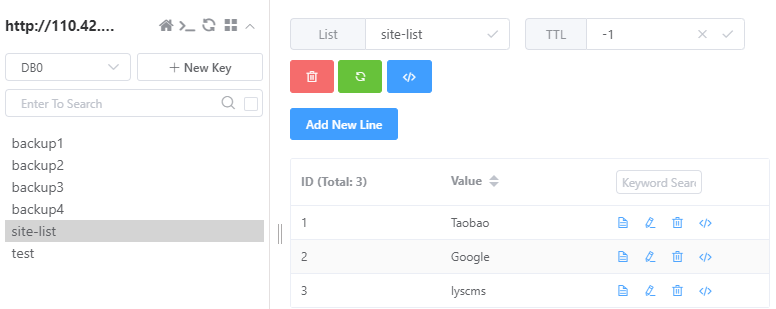
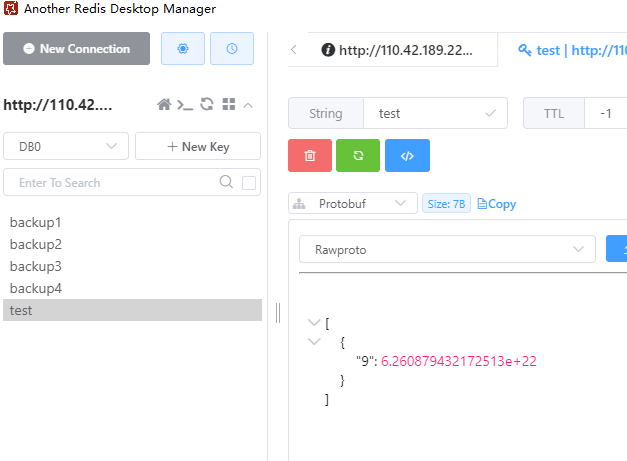
值得注意的是,在可视化界面里,有一个值叫TTL,这个就是key的生存时间,其为-1说明该键是永久存在的;如果为其他值,说明其在生存时间有限。
5.2.4 高级使用
上述都是Redis简单的键值存储,在实际Java开发中,经常会使用连接池来管理Redis,具体如下代码:
package org.example;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* Created with IntelliJ IDEA.
* Explain:Redis连接池
*/
public final class RedisPool {
//Redis服务器IP
private static String ADDR = "127.0.0.1";
//Redis的端口号
private static Integer PORT = 6379;
//访问密码
private static String AUTH = "yfy131";
//可用连接实例的最大数目,默认为8;
//如果赋值为-1,则表示不限制,如果pool已经分配了maxActive个jedis实例,则此时pool的状态为exhausted(耗尽)
private static Integer MAX_TOTAL = 1024;
//控制一个pool最多有多少个状态为idle(空闲)的jedis实例,默认值是8
private static Integer MAX_IDLE = 200;
//等待可用连接的最大时间,单位是毫秒,默认值为-1,表示永不超时。
//如果超过等待时间,则直接抛出JedisConnectionException
private static Integer MAX_WAIT_MILLIS = 10000;
private static Integer TIMEOUT = 10000;
//在borrow(用)一个jedis实例时,是否提前进行validate(验证)操作;
//如果为true,则得到的jedis实例均是可用的
private static Boolean TEST_ON_BORROW = true;
private static JedisPool jedisPool = null;
/**
* 静态块,初始化Redis连接池
*/
static {
try {
JedisPoolConfig config = new JedisPoolConfig();
/*注意:
在高版本的jedis jar包,比如本版本2.9.0,JedisPoolConfig没有setMaxActive和setMaxWait属性了
这是因为高版本中官方废弃了此方法,用以下两个属性替换。
maxActive ==> maxTotal
maxWait==> maxWaitMillis
*/
config.setMaxTotal(MAX_TOTAL);
config.setMaxIdle(MAX_IDLE);
config.setMaxWaitMillis(MAX_WAIT_MILLIS);
config.setTestOnBorrow(TEST_ON_BORROW);
jedisPool = new JedisPool(config,ADDR,PORT,TIMEOUT,AUTH);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取Jedis实例
* @return
*/
public synchronized static Jedis getJedis(){
try {
if(jedisPool != null){
Jedis jedis = jedisPool.getResource();
return jedis;
}else{
return null;
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
public static void returnResource(final Jedis jedis){
//方法参数被声明为final,表示它是只读的。
if(jedis!=null){
jedisPool.returnResource(jedis);
//jedis.close()取代jedisPool.returnResource(jedis)方法将3.0版本开始
//jedis.close();
}
}
}之所以使用连接池,是因为jedis连接资源的创建与销毁是很消耗程序性能,所以jedis为我们提供了jedis的池化技术,jedisPool在创建时初始化一些连接资源存储到连接池中,使用jedis连接资源时不需要创建,而是从连接池中获取一个资源进行redis的操作,使用完毕后,不需要销毁该jedis连接资源,而是将该资源归还给连接池,供其他请求使用。
Redis的使用其实非常复杂,而且在由于互联网大厂日益增多的高并发需求,Redis因其快速存取的缓存特性,成为了这些应用的首要选择,更加复杂的使用在本文就不再展示。










