本文最后更新于781 天前,其中的信息可能已经过时,如有错误请发送邮件到mapleleaf2333@gmail.com
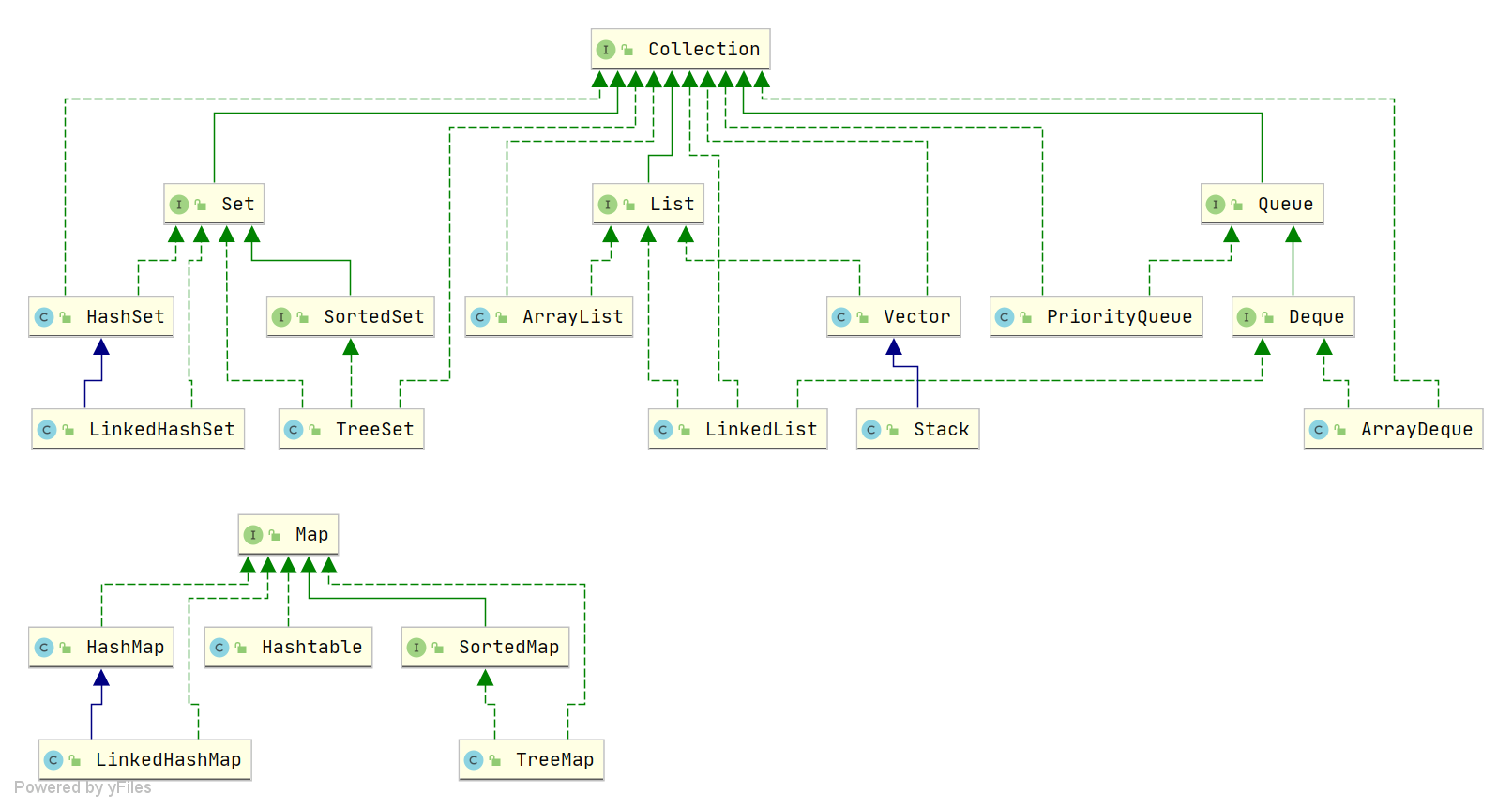
Collection
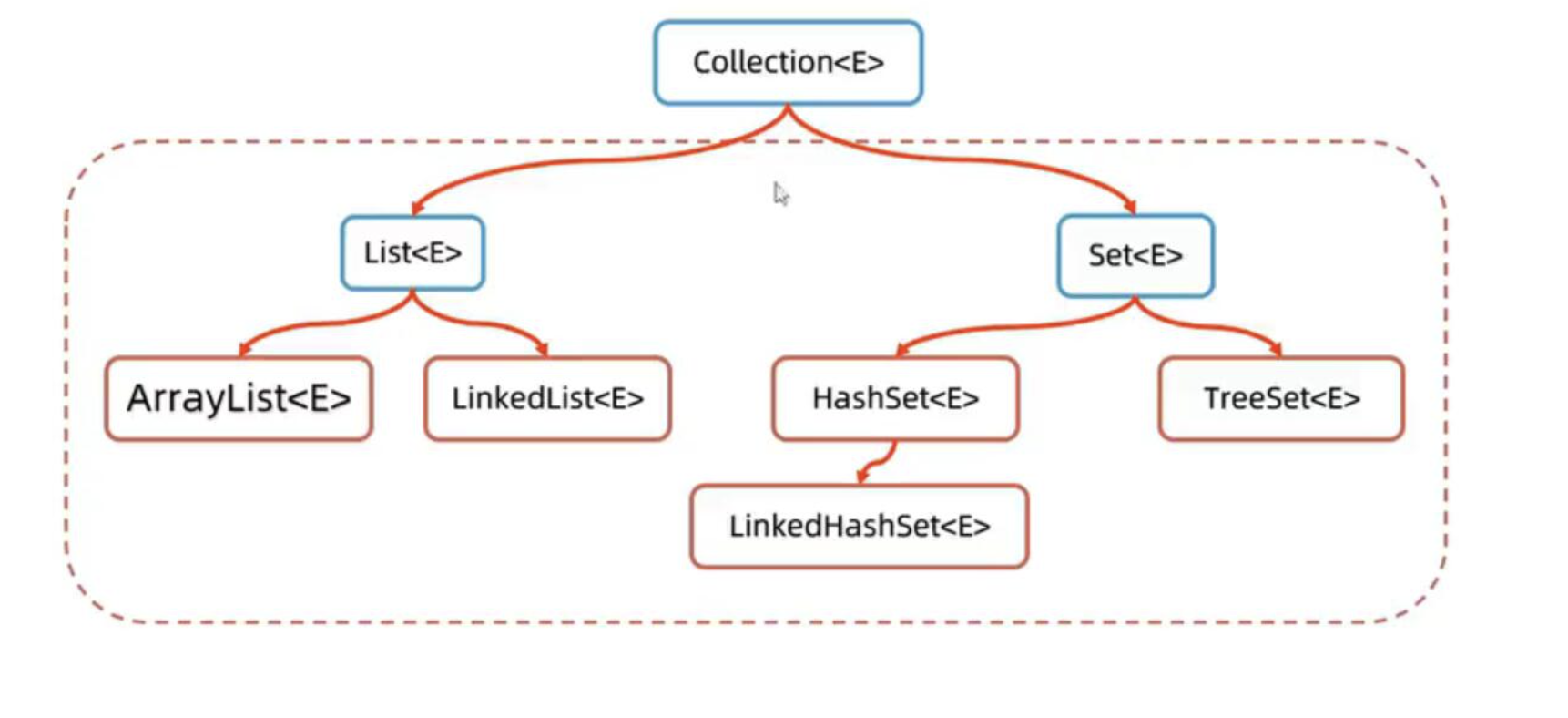
常用方法:
- add(E e):添加数据
- clear():清空
- isEmpty():判空
- remove(Object o):移除单实例个
- Contains(Object o):判断集合是否包含某个数据
- toArray():集合转数组
ArrayList
扩容
- 利用无参构造器创建时,底层默认创建长度为0数组
- 添加第一个元素,创建长度为10的数组
- 存满时,扩容1.5倍
- 一次性存储的量超过1.5倍扩容的量,则新数组扩容长度以能完全放下新数据为准
适用场景
根据随机索引查数据or数据量不大
LinkedList
基于双链表
特点:查询慢,增删相对快,对首尾增删改查极快
Map
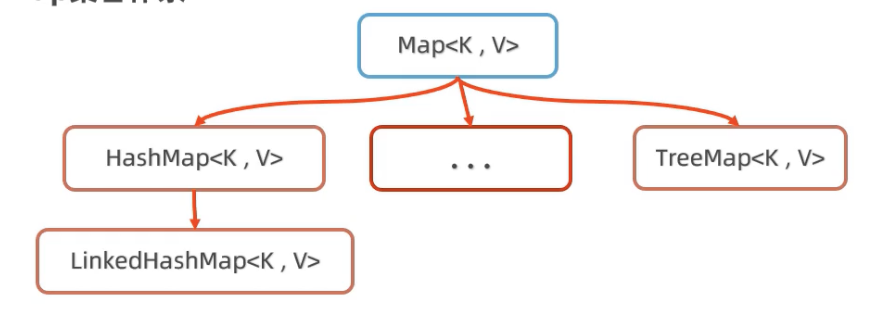
常用方法:
- put(K key,V value):插入
- remove(Object key):按键删除
- values():返回该map的所有值的collection视图
HashMap底层原理
数组+链表+红黑树
初始化时分配16个单位的存储空间,每次存入一个值时,会将KV封装成一个Entry,然后通过键和哈希函数计算哈希值,通过对数组求余确定该KV的存储位置。当有一个位置已经有一个Entry时,调用equal方法比较,相等不存,不等则存,JDK8之后会将新Entry挂在旧的Entry下面形成链表。
当存储的数组使用率大于75%时,会将哈希数组的存储空间翻倍实现扩容,初始数组大小一般为16,第一次扩容通常时已经有12个单位的位置被占用。
而当数组长度>=64,且某一位置链表长度大于8时,链表将自动转成红黑树以提高HashMap的效率。
List, Set, Queue, Map 四者的区别
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),”x” 代表 key,”y” 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。