本文最后更新于660 天前,其中的信息可能已经过时,如有错误请发送邮件到mapleleaf2333@gmail.com
课程链接:书生·浦语大模型全链路开源体系
InternLM2的模型选用
提供了两种规格的模型:
- 7B规格:为轻量级研究提供轻便且性能不俗的模型
- 20B规格:综合性更强,支持更复杂场景
每种规格的模型都提供了三个版本:
- InternLM2-Base:高质量、可塑性强的模型基座
- InternLM2:基于Base,在多个能力方向进行强化,并保持通用语言能力,最推荐使用
- InternLM2-Chat:在Base基础上,经过SFT和RLHF,面向会话交互进行优化的模型
SFT:监督微调(Supervised Fine-Tuning),指在有监督的数据上进一步训练预训练模型,以改善其在特定任务上的表现
RLHF:基于人类反馈的强化学习(Reinforcement Learning from Human Feedback),是一种用于训练大型语言模型(LLMs)的技术,旨在使模型生成的输出更符合人类的期望和偏好。
InternLM2的亮点
- 具备超长上下文能力:在20万token上下文中,几乎完美实现“大海捞针”
- 综合性能全面提升:推理、数学、代码能力强,InternLM2-Chat-20B在重点评测毕竟ChatGPT
- 优秀的对话和创作体验:在AlpacaEval2超越GPT-3.5和Gemini Pro
- 工具调用能力整体升级:可靠支持工具多轮调用,复杂智能体搭建
- 突出的数理能力和实用的数据分析功能:加入代码解释器在GSM8K和MATH达到和GPT-4相仿水平
从模型到应用
典型流程:
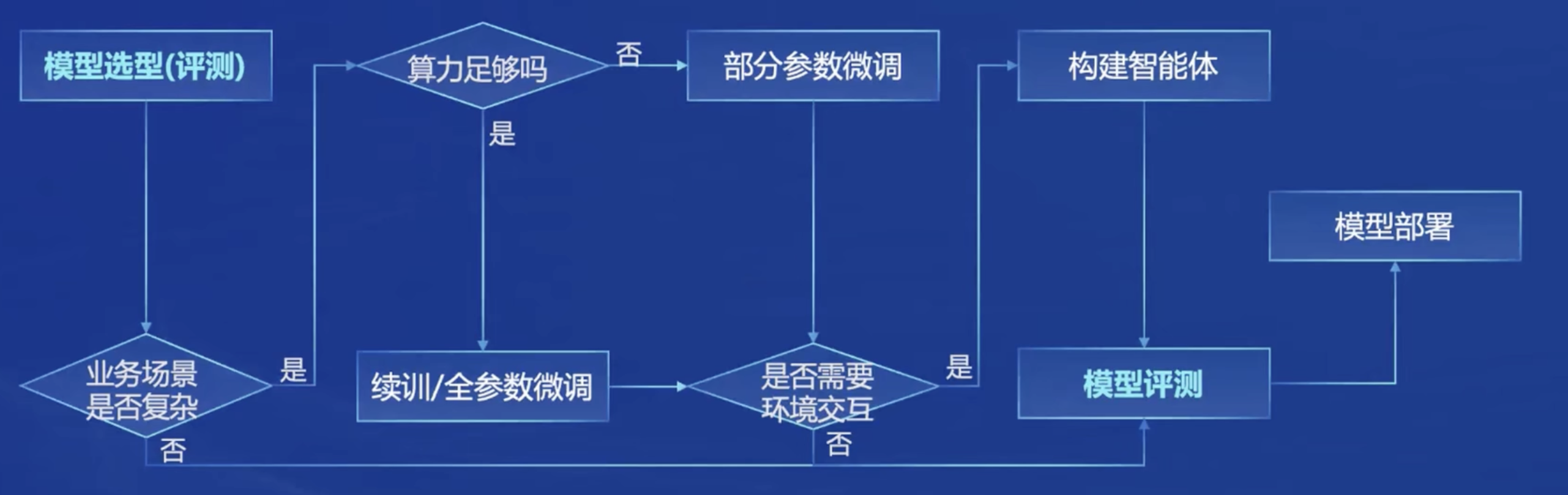
书生浦语打造了全链条的开源开放体系满足从模型到应用的流程:
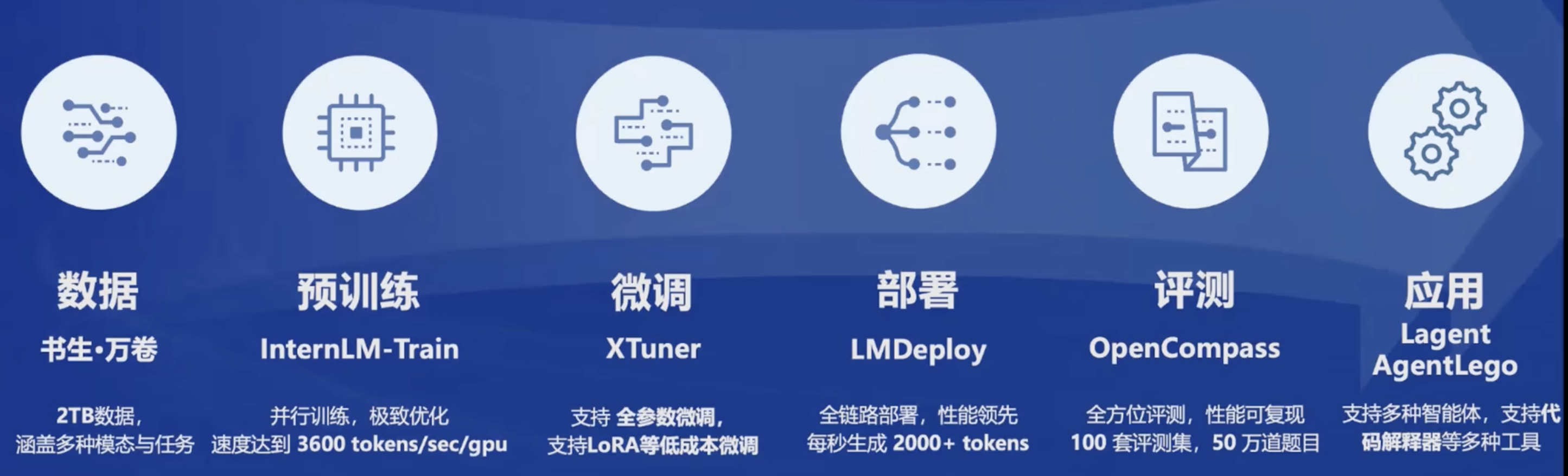
开源体系介绍
数据集:书生·万卷
提供丰富的高质量语料数据:
- 书生·万卷1.0:超1TB的文档数据,超140GB的图像-文本数据集,超140GB的视频数据
- 书生·万卷CC:包括2013-2023年互联网的数据内容,数据来源丰富,从90个dumps的1300亿份原始数据中“萃取”1.38%内容,且安全密度高
以上数据均可以通过OpenDataLab获取
预训练
- 高可扩展性,支持从8卡到千卡训练,千卡加速效率达92%
- 兼容主流技术生态如HuggingFace
- 开箱即用
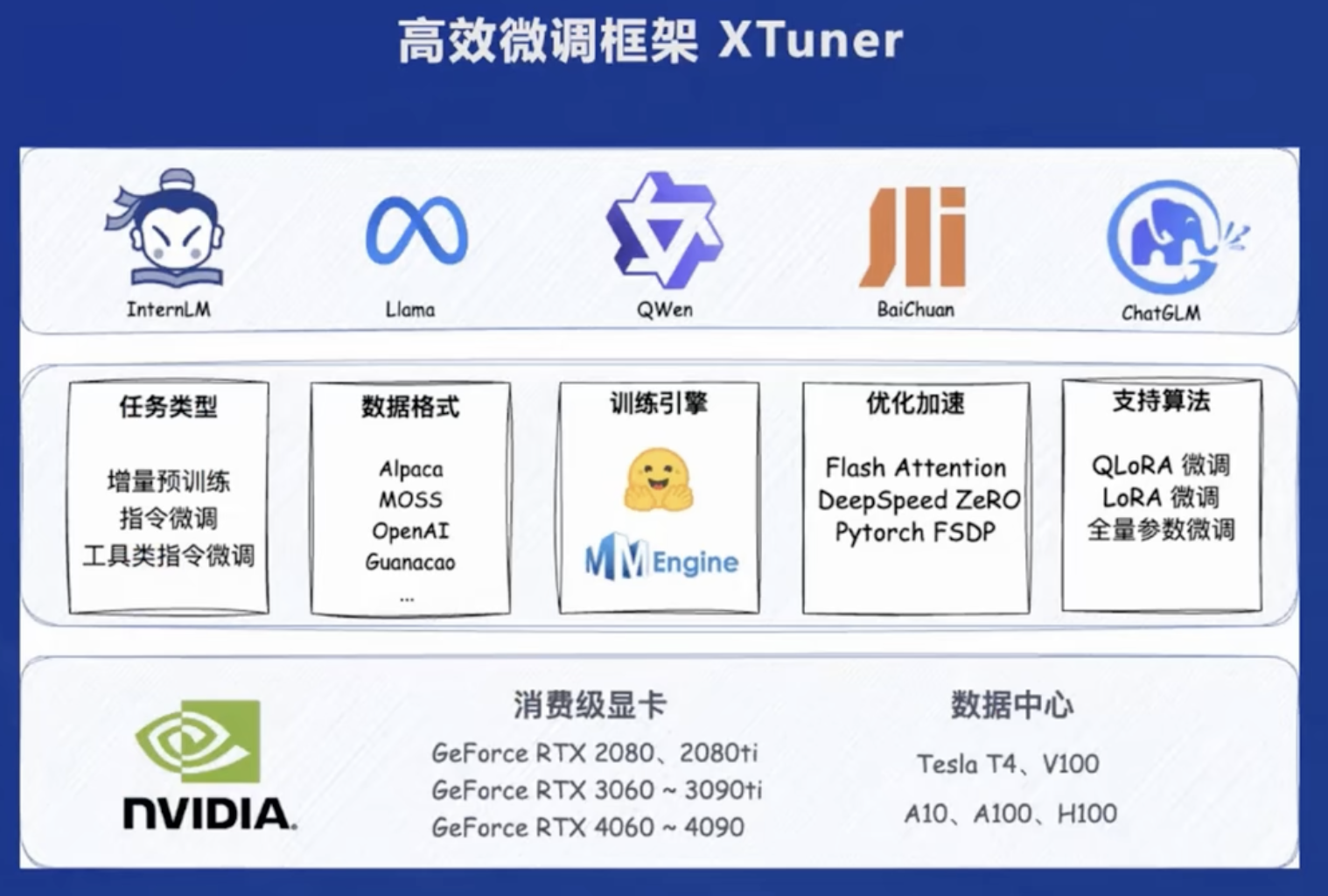
微调:XTuner
先介绍两种常用的微调方式:
增量续训:让基座模型学习新知识(如某些垂类领域知识),常用文章、书籍、代码作为训练数据
有监督微调:让模型学会理解各种指令进行对话,常用高质量对话、问答作为训练数据
开发了XTuner微调框架,该框架适配多种生态,包并适配多种硬件
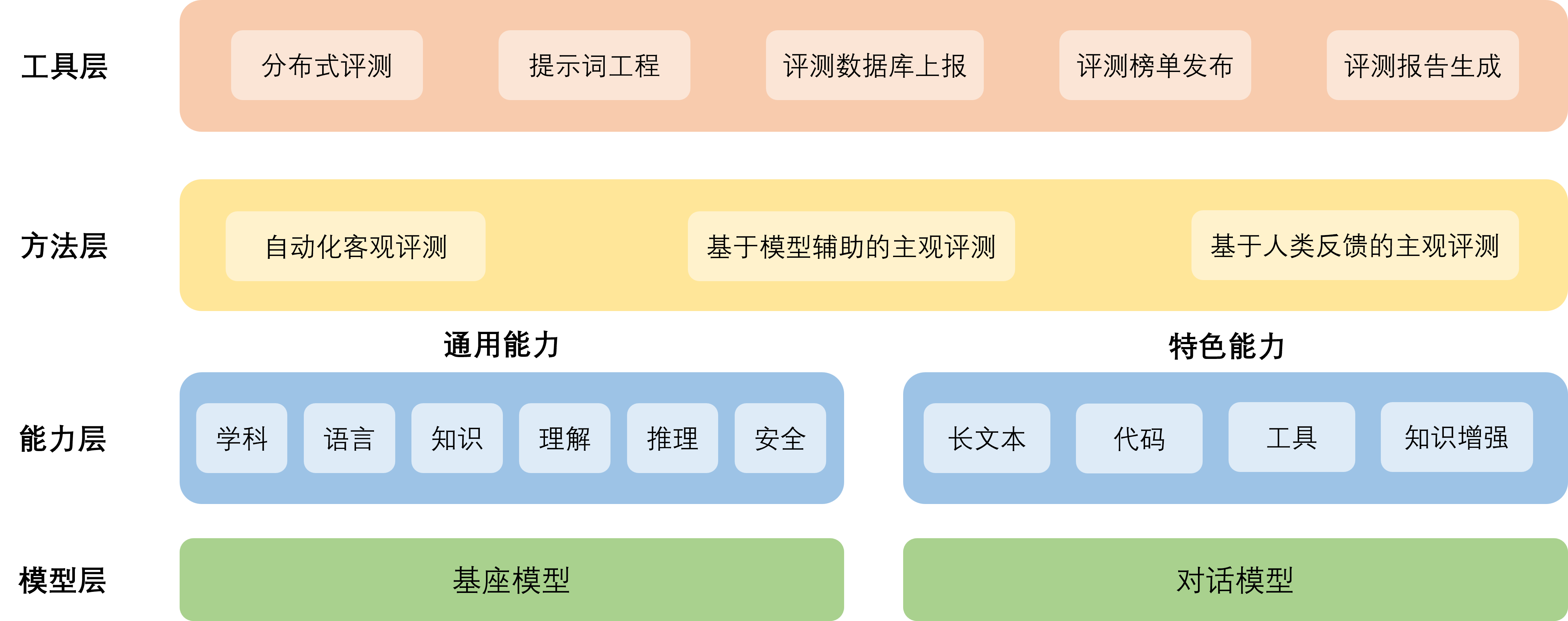
评测体系:OpenCompass
- CompassRank:中立全面的性能榜单,评估不同的模型
- CompassKit:大模型评测全栈工具链,包括模型推理接入、长文本能力评测等
- CompassHub:构建高质量评测基准社区
部署:LMDeploy
LMDeploy提供大模型在GPU上部署的全流程解决方案,包括模型轻量化、推理和服务
- 高效推理引擎:持续批处理技巧,深度优化的低比特计算kernels,模型并行,高效的k/v缓存管理机制
- 完备易用的工具链:量化、推理、服务全流程,无缝对接OpenCompass评测推理精度,多维度推理速度评测工具
- 支持交互式推理,不为历史对话买单
应用
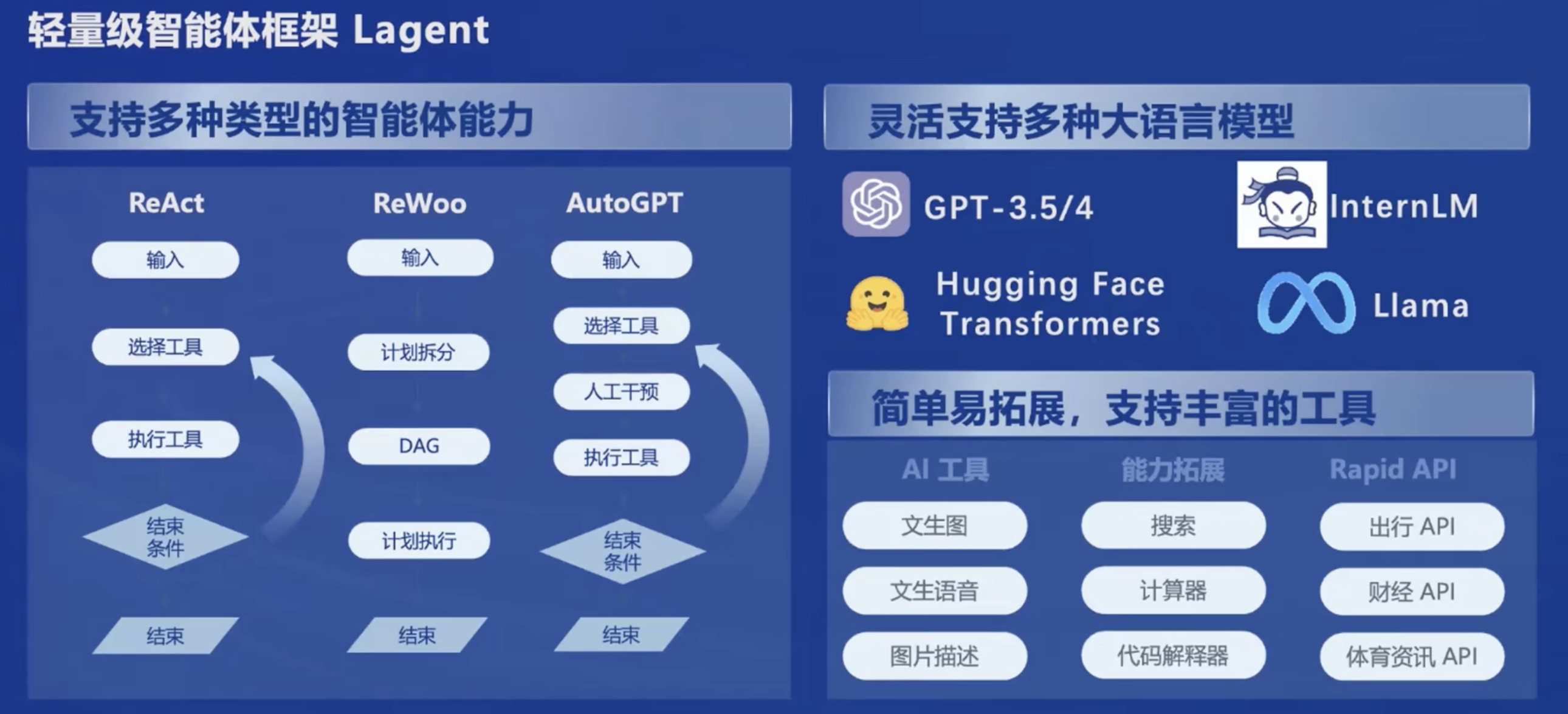
提供多模态智能体工具箱AgentLego:
- 提供大量视觉、多模态领域前沿算法功能
- 支持多个主流智能体系统,如LangChain,Transformers Agent,lagent等
- 灵活的多模态工具调用接口,支持各类输入输出格式的工具函数
- 一键式远程工具部署